Pipeline and Function
Pipeline
A pipeline is a defined container-native workflow. It consists of units called functions, which determine the behavior of the workflow by defining the execution order between functions, exception handling, input and output, and connections to entities.
How to Use the Pipeline
- Add to the Canvas:
- The Name is required. (Only alphanumeric characters and hyphens are allowed)
- Make sure to connect it with a trigger.
- You must add at least one function. (Add by clicking the "+" button in the menu that appears when clicking the pipeline box)
- Running the Pipeline:
- The pipeline can be invoked from a connected trigger on the canvas using the runTriggerPipeline() function.
Function
Defines a unit of processing within the pipeline. Each function has one arbitrary Docker image and runs on Kubernetes according to the order specified in the pipeline.
Connections to entities vary based on layering. Please refer to here for details regarding layers.
How to Use the Function
- The Name is required. (Only alphanumeric characters and hyphens are allowed)
- Please input the Docker image in the Image field.
- The container image must have either ENTRYPOINT or CMD set.
Input
- You can add files to be volume-mounted into the function container under "Input." Choose from the following types to add:
- Entity
- Values can be read from an entity.
- For layered entities, a GET is performed using the Layer ID inherited from the trigger.
- Filesystem
- Used to receive values from the Filesystem Output of the previous function. Set the same Name as the Output you wish to pass.
- Injection
- Allows passing values inserted via Blueprint into the function. Used to pass pre-defined files like configuration files or scripts.
- Entity
Output
- You can add files to be outputted from the function container under "Output." Choose from the following types to add:
- Entity
- Values can be written to an entity.
- For layered entities, a POST is performed using the Layer ID inherited from the trigger.
- Filesystem
- Used to pass values to the Filesystem Input of subsequent functions.
- Entity
Artifact Transfer
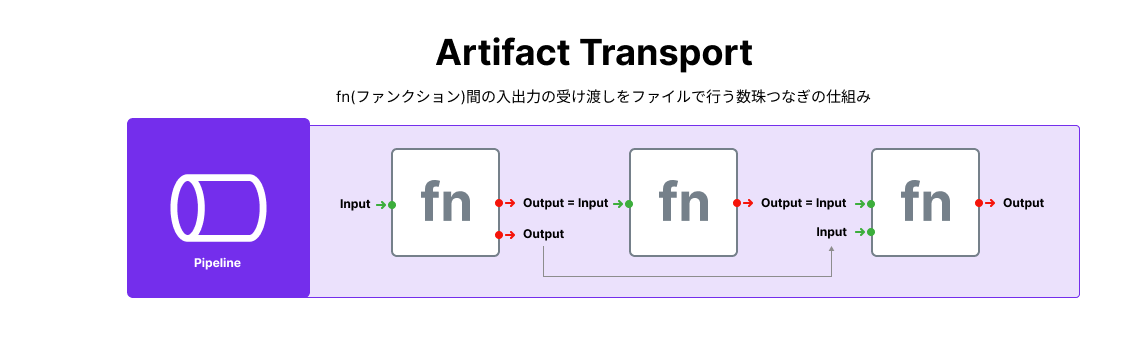
- The data and files generated during processing by each function are called Artifact.
- This feature allows for the transfer of Artifacts between multiple functions operating within the pipeline.
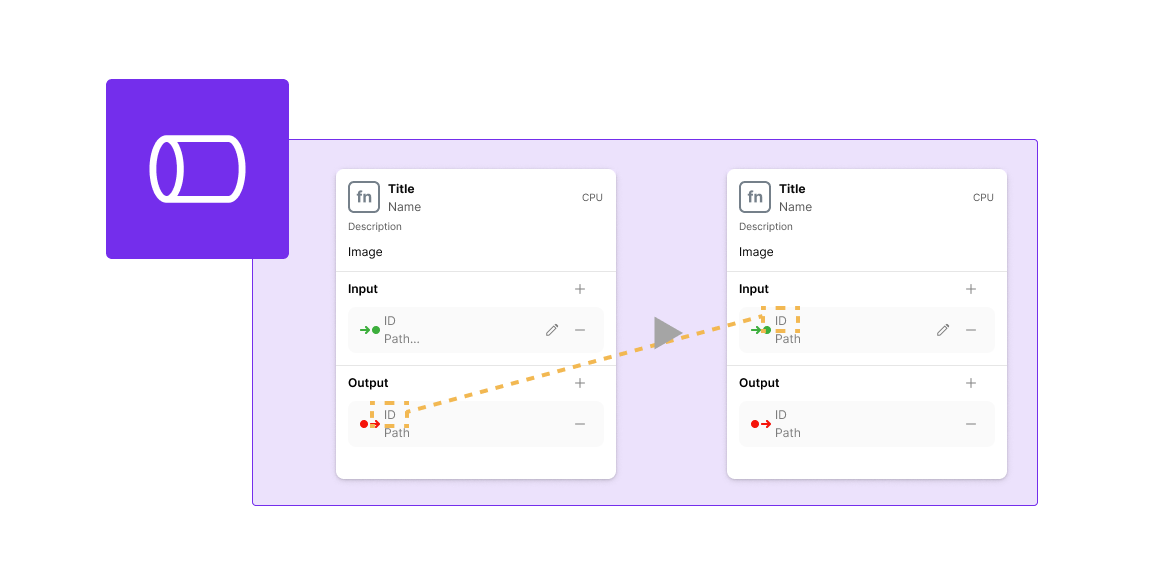
- Utilize the aforementioned Input/Output to use the output as input for functions within the same pipeline.
Usage
- Ensure that the Artifact ID being utilized from an upstream function is the same for Input/Output.
Environment Variables
- You can add environment variables that can be referenced from within the function container under "Environment variables".
- The following environment variables are set automatically. For details, please refer to Reserved Environment Variables.
- EBS_LAYERID: Layer ID (inherited from the trigger. If the trigger is not layered, an empty string will be set)
- EBS_WORKSPACEID: Workspace ID
- EBS_PIPELINEID: ID assigned during the execution of the pipeline
Storage
- A filesystem storage used for the persistence of data. Details can be checked from Storage.
Notes
- If the connected trigger is not layered, the Layer ID cannot be obtained, so connections to Input/Output for layered entities cannot be made.
FailureHandler
You can define exception handling for cases where there are abnormalities in pipeline functions, acting as a runtime failure handler. Like the pipeline, it consists of one or more functions.
- Adding to the Canvas
- Please add it using the button from the pipeline menu.
- FailureHandler can have functions added just like the pipeline.
- Execution Timing of FailureHandler
- The FailureHandler will be executed if a pipeline function terminates abnormally and there is a FailureHandler defined.
- Input
- "Entity", "Filesystem" Input
- Similar to normal functions.
- "Exception" Input
- Can receive values from the "Filesystem" Output of the pipeline function, similar to "Filesystem." It will only mount if the Output has been successfully generated during the execution of the FailureHandler.
- "Injection" Input
- Not supported.
- "Entity", "Filesystem" Input
- Output
- Similar to normal functions.
- Regarding the Pipeline Layer
- The Layer ID during pipeline execution is inherited from the initiating trigger. Triggers monitor entities by Layer ID, making Layer ID uniquely determined in reactive events. If the trigger does not monitor layered entities, the Layer ID will be empty. The layer affects the running pipeline as described below.
- The Layer ID can be obtained from FailureHandler’s function container via the environment variable
EBS_LAYERID.- If layered entities are connected to Input/Output, the Layer ID inherited from the trigger will be applied.
- Pipelines connected to layered entities cannot be invoked from non-layered triggers.