RAGシステム with ハイブリッド検索
LLMを使ったアプリケーション開発のフレームワークであるLangChainを使って、RAGシステムを構築できます。リトリーバーにBM25アルゴリズムを利用でき、ベクトル検索とのハイブリッド検索に対応しています。
Azure OpenAI Service か OpenAI API のAPIキーが必要です。
紹介動画
概要
想定ユーザー
- RAGシステムを実装したいユーザー。
- PDFやWebページのドキュメントをベクトルデータと合わせてOpenSearchに保存したいユーザー。
- 検索に、ベクトル検索・BM25・ハイブリッド検索を使用したいユーザー。
テンプレート動作
- 入力
- シークレット
AZURE_AI_API_KEY- Azure OpenAI Serviceを使用する場合、そのAPIキーを入力する。
- OpenAI APIを使用するでも、OpenAIのAPIキーを入力すると、他の変数の設定を変更することなく利用できる。OpenAIのAPIキーを設定するためのシークレットを別に設ける場合は、
chatknowledge for adminSideAppのEnvironment variablesOPENAI_API_KEYの値の${{SECRET.AZURE_AI_API_KEY}}のAZURE_AI_API_KEYの部分を、対応するシークレットのキーに変更する。
OPENSEARCH_PASSWORD- OpenSearchで使用するためのパスワードを設定する。値は任意。
chatknowledge for adminSideAppのEnvironment variablesSTREAMLIT_SERVER_PORT- Streamlitが起動するポート
8080を指定する。
- Streamlitが起動するポート
OPENAI_API_TYPE- Azure OpenAI Serviceの場合は値を
azure、OpenAI APIの場合は値をopenaiとする。
- Azure OpenAI Serviceの場合は値を
OPENAI_API_VERSION- Azure OpenAI Serviceの場合のみ使用するAzure OpenAI APIバージョン。値は
2023-10-01-previewなど。OpenAI APIを使用する場合は設定しない。
- Azure OpenAI Serviceの場合のみ使用するAzure OpenAI APIバージョン。値は
OPENAI_API_BASE- Azure OpenAI Serviceの場合のみ使用するAzure OpenAI APIのベースURL。値は基本的に
https://{replace-me}.openai.azure.com/の形式。OpenAI APIを使用する場合は設定しない。
- Azure OpenAI Serviceの場合のみ使用するAzure OpenAI APIのベースURL。値は基本的に
OPENAI_API_KEY- Azure OpenAI ServiceまたはOpenAI APIのAPIキー。この値は
${{SECRET.AZURE_AI_API_KEY}}のように設定し、APIキーの値は対応するシークレットに格納する。
- Azure OpenAI ServiceまたはOpenAI APIのAPIキー。この値は
OPENSEARCH_URL- OpenSearchサーバーのURL。
http://{opensearch SideAppが存在するWorkspace名}-{opensearch SideAppのID}:8080の形式で指定する。
- OpenSearchサーバーのURL。
VECTOR_STORE- ベクターストアの種類。値は
Opensearch。
- ベクターストアの種類。値は
OPENSEARCH_INDEX- DBに�ドキュメントを登録する際のindex名。
OPENAI_CHUNK_SIZE- ドキュメントロード時の最大チャンクサイズ。
CHAT_MODEL_LIST- 使用するモデルのリスト。
gpt-35-turbo-16k,gpt-4,gpt-3.5-turboのように、カンマ区切りで指定する。
- 使用するモデルのリスト。
ALLOW_UPLOAD- ドキュメントのアップローダーを表示する場合は値を
trueとする。
- ドキュメントのアップローダーを表示する場合は値を
LOG_ENTITY- 会話履歴を保存するために使用するEntity名。他のアセットと組み合わせて使う場合に利用する。このアセット単体で使用する場合は設定不要。
OPENSEARCH_INITIAL_ADMIN_PASSWORD- OpenSearchで設定するパスワード。この値は
${{SECRET.OPENSEARCH_PASSWORD}}のように指定し、実際のパスワードは対応するシークレットに格納する。
- OpenSearchで設定するパスワード。この値は
PAST_CONTEXT- チャットでAPIにリクエストを投げる際に含める過去の会話(Q&A)の数。
- Injection機能による初期設定
opensearchSideAppのInjectionファイル/usr/share/opensearch/config/opensearch.ymlのcluster.nameの値を、各環境のクラスター名 (URLのapp.{env-id}.studio.exabase.aiの{env-id}の部分) に置き換える。Opensearch DashboardSideAppのInjectionファイル/usr/share/opensearch/config/opensearch.ymlの{namespace-id}をCanvasのネームスペースIDに置き換える。
- ドキュメントの登録
- デプロイした後、
chatknowledge for adminSideAppに接続されたエンドポイントのURLからRAGシステムの管理画面を開き、RAGシステムで用いるためのPDFまたはWebページのドキュメントを登録する。
- デプロイした後、
- チャット入力
- ドキュメントを登録した後、RAGシステム管理画面下部のチャット欄からテキストを入力する。
- シークレット
- Output
- チャット入力に対して、ドキュメントを踏まえた回答が得られる。
- Function
- 検索にベクトル検索、BM25、ハイブリッド検索を用い、登録されたドキュメントに基づいてチャットボットが回答する。
- PDFやWebページのドキュメントをベクトルデータと合わせてOpenSearchに保存する。
- 登録したドキュメントをOpenSearchダッシュボードで確認する。
利用方法
単体での動作確認
- Canvasでシークレットとして下記を設定する。
AZURE_AI_API_KEY- Azure OpenAI Serviceを使用する場合、そのAPIキーを入力する。
- OpenAI APIを使用するでも、OpenAIのAPIキーを入力すると、他の変数の設定を変更することなく利用できる。OpenAIのAPIキーを設定するためのシークレットを別に設ける場合は、
chatknowledge for adminSideAppのEnvironment variablesOPENAI_API_KEYの値の${{SECRET.AZURE_AI_API_KEY}}のAZURE_AI_API_KEYの部分を、対応するシークレットのキーに変更する。
OPENSEARCH_PASSWORD- OpenSearchで使用するためのパスワードを設定する。値は任意。
- Canvasで
chatknowledge for adminSideAppのEnvironment variablesとして下記を設定する。STREAMLIT_SERVER_PORT- Streamlitが起動するポート
8080を指定する。
- Streamlitが起動するポート
OPENAI_API_TYPE- Azure OpenAI Serviceの場合は値を
azure、OpenAI APIの場合は値をopenaiとする。
- Azure OpenAI Serviceの場合は値を
OPENAI_API_VERSION- Azure OpenAI Serviceの場合のみ使用するAzure OpenAI APIバージョン。値は
2023-10-01-previewなど。OpenAI APIを使用する場合は設定しない。
- Azure OpenAI Serviceの場合のみ使用するAzure OpenAI APIバージョン。値は
OPENAI_API_BASE- Azure OpenAI Serviceの場合のみ使用するAzure OpenAI APIのベースURL。値は基本的に
https://{replace-me}.openai.azure.com/の形式。OpenAI APIを使用する場合は設定しない。
- Azure OpenAI Serviceの場合のみ使用するAzure OpenAI APIのベースURL。値は基本的に
OPENAI_API_KEY- Azure OpenAI ServiceまたはOpenAI APIのAPIキー。この値は
${{SECRET.AZURE_AI_API_KEY}}のように設定し、APIキーの値は対応するシークレットに格納する。
- Azure OpenAI ServiceまたはOpenAI APIのAPIキー。この値は
OPENSEARCH_URL- OpenSearchサーバーのURL。
http://{opensearch SideAppが存在するWorkspace名}-{opensearch SideAppのID}:8080の形式で指定する。
- OpenSearchサーバーのURL。
VECTOR_STORE- ベクターストアの種類。値は
Opensearch。
- ベクターストアの種類。値は
OPENSEARCH_INDEX- DBにドキュメントを登録する際のindex名。
OPENAI_CHUNK_SIZE- ドキュメントロード時の最大チャンクサイズ。
CHAT_MODEL_LIST- 使用するモデルのリスト。
gpt-35-turbo-16k,gpt-4,gpt-3.5-turboのように、カンマ区切りで指定する。
- 使用するモデルのリスト。
ALLOW_UPLOAD- ドキュメントのアップローダーを表示する場合は値を
trueとする。
- ドキュメントのアップローダーを表示する場合は値を
LOG_ENTITY- 会話履歴を保存するために使用するEntity名。他のアセットと組み合わせて使う場合に利用する。このアセット単体で使用する場合は設定不要。
OPENSEARCH_INITIAL_ADMIN_PASSWORD- OpenSearchで設定するパスワード。この値は
${{SECRET.OPENSEARCH_PASSWORD}}のように指定し、実際のパスワードは対応するシークレットに格納する。
- OpenSearchで設定するパスワード。この値は
PAST_CONTEXT- チャットでAPIにリクエストを投げる際に含める過去の会話(Q&A)の数。
- Canvasで
opensearchSideAppのInjectionファイル/usr/share/opensearch/config/opensearch.ymlのcluster.nameの値を、各環境のクラスター名 (URLのapp.{env-id}.studio.exabase.aiの{env-id}の部分) に置き換える。 - Canvasで
Opensearch DashboardSideAppのInjectionファイル/usr/share/opensearch/config/opensearch.ymlの{namespace-id}をCanvasのネームスペースIDに置き換える。 - デプロイボタンを押し、デプロイの完了を待つ。
chatknowledge for adminSideAppに接続されたEndpointのURL (https://studio.{env-id}.studio.exabase.ai/{namespace-id}/ws/chatknowledge-admin/) から、管理画面にアクセスする。- 管理画面左側の設定項目を入力する。
- "Chat Settings" と "Text Embedding Settings" の "Model" では、使用するモデル名を選択する。
- "Deployment" には、Azure OpenAI Serviceの場合、使用するデプロイメント名を入力する。OpenAI APIの場合は入力不要。
- "Search Method" では、使用する検索アルゴリズムを選択する。
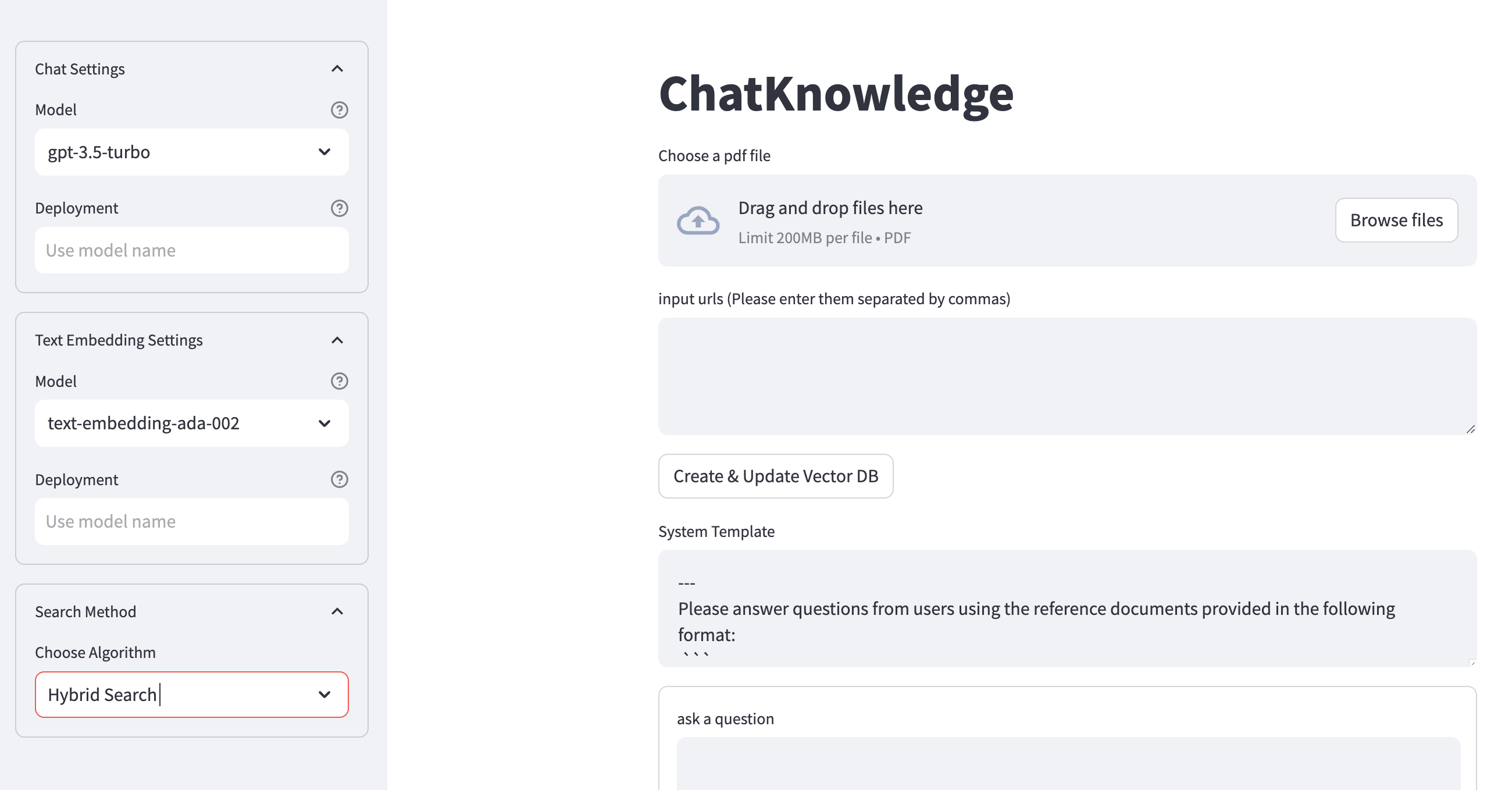
- 管理画面から、ドキュメントを登録する。
- PDFファイルの内容を登録する場合、 "Choose a pdf file" のフォームから使用するPDFファイルをアップロードする。
- Webページの内容を登録する場合、 "input urls" のフォームにURLをカンマ区切りで入力する。
- PDFファイルアップロードまたはURL入力の後、 "Create & Update Vector DB" のボタンを押し、登録が完了するのを待つ。
- 管理画面下部の "ask a question" のフォームからテキストを入力して "Go" ボタンを押すと、登録したドキュメントを踏まえた回答が得られる。
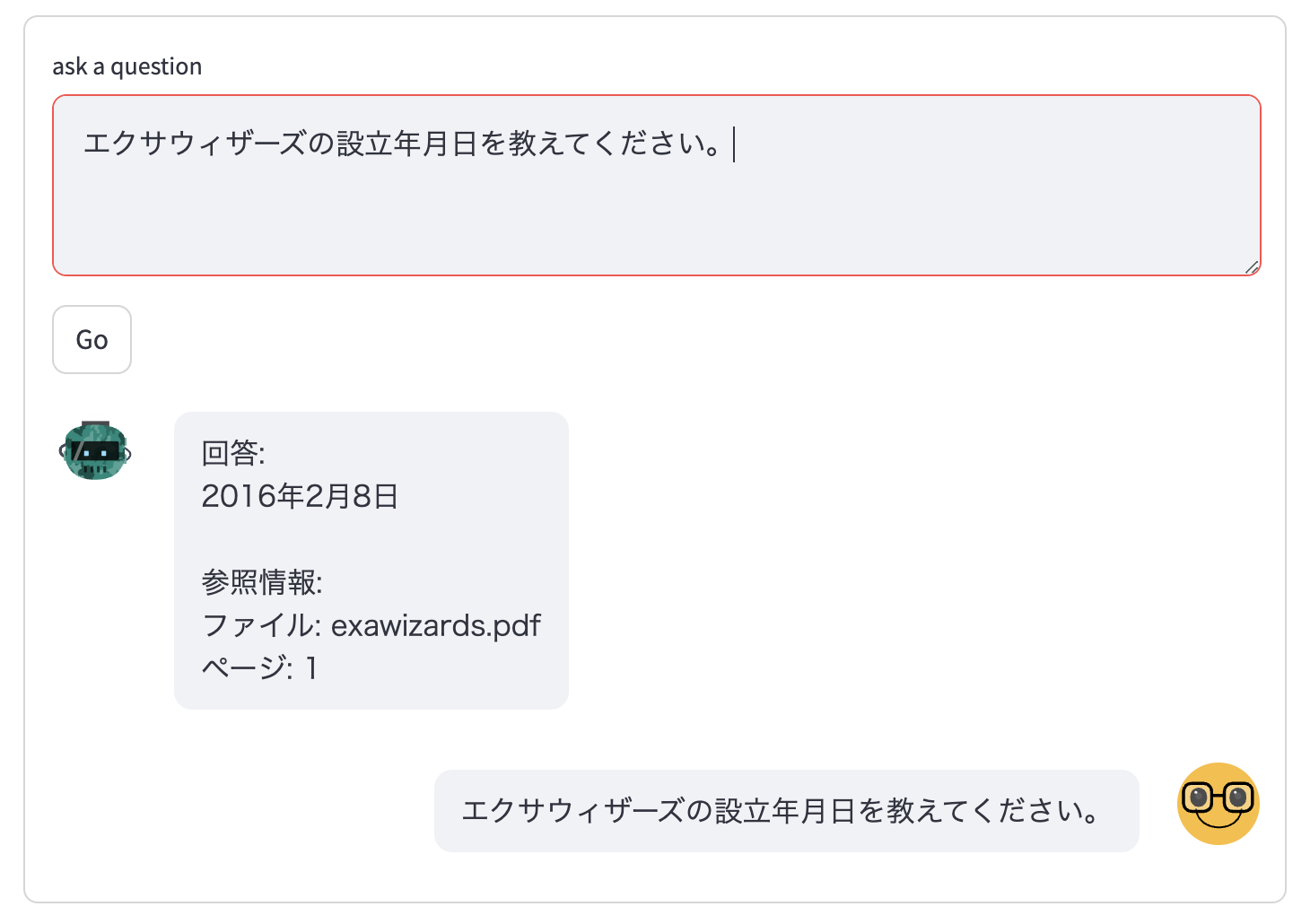
- 登録したドキュメントデータをOpenSearchダッシュボードで確認する場合、以下の操作を行う。
Opensearch DashboardSideAppに接続されたEndpointのURL (https://studio.{env-id}.studio.exabase.ai/{namespace-id}/ws/opensearch-dashboard/) から、OpenSearchダッシュボードにアクセスする。- OpenSearchダッシュボードのメニューから "Discover" を開き、 "Create index pattern" から、
chatknowledge for adminSideAppのEnvironment variablesのOPENSEARCH_INDEXで設定し��た名称 (デフォルト値は chatknowledge) のインデックスパターンを作成する。 - 再度OpenSearchダッシュボードのメニューの "Discover" を開くと、登録したドキュメントデータを確認できる。
他のアセットとの連携
- 会話履歴を保存する場合、Entityを経由して保存できる。DB等に保存する場合は、Entityに接続するTriggerやPipelineを組み合わせて実装すると良い。Entityの配置や会話内容のデータについては下記。
chatknowledge for adminSideAppのEnvironment variablesのLOG_ENTITYの値と一致するIDのData Entityを、同じWorkspace内に配置すると、チャット時Entityに会話内容が送られる。
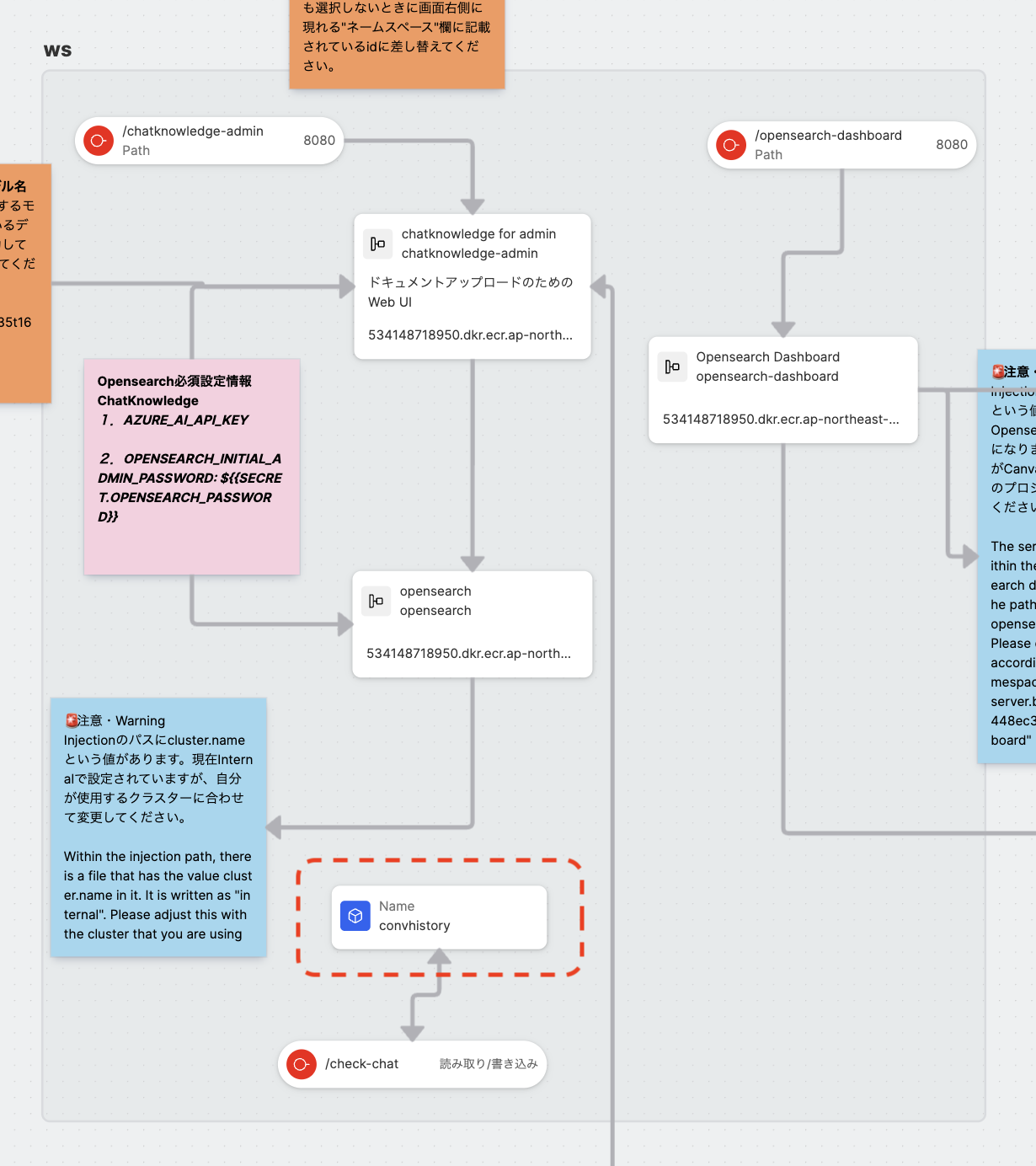
- Data Entityの
/dataAPIエンドポイント (上記画像のように設定してEntityに接続したEndpointにリクエストを投げる場合のURLはhttps://studio.{env-id}.studio.exabase.ai/{namespace-id}/ws/check-chat/data) にGETリクエストを送ると、{"data": "<JSON文字列>"}のようなJSONを得る。<JSON文字列>をパースすると、JavaScriptの場合、下記キーを有するオブジェクトが得られる。apitype:chatknowledge for adminSideAppのEnvironment variablesのOPENAI_API_TYPEに設定した値。appid: 本アセットの場合、値は"chatknowledge"となる。convid: 会話のIDの文字列。messages: チャットメッセージに関するオブジェクトの配列。そのオブジェクトは下記キーを有する。role: メッセージ送信者のロールの文字列。基本的に配列の先頭のものの値が"user"(チャット入力側) で、次のものの値が"assistant"(チャットボットの出力側)。content: メッセージ内容の文字列。ただし、roleが"user"の場合、チャット入力欄以外の命令文も含む。
model: チャットで用いるために選択したモデル名の文字列。例えば"gpt-3.5-turbo"のような値となる。timestamp: タイムスタンプの文字列(JST)。例えば"2024-08-15 11:41:16"のような値となる。tokensize: 対応するOpenAIのAPIコールで使用された総トークン数。userid: 本アセットの場合、値は"chatknowledge"となる。
関連情報
- RAG
- RAG (Retrieval-Augmented Generation, 検索による拡張生成) は、LLMを使う際に業務で扱うデータなどの関連情報をデータベースから検索して生成プロセスに取り込む手法です。
- https://exawizards.com/exabase/studio/blog/27871/
- ベ��クトル検索
- ベクトル検索とは、データを数値ベクトル(数値の配列)をして表現し、ベクトル間の距離(類似度)を計算する検索手法です。
- BM25
- BM25は、キーワード検索で用いられるもので、単語の出現頻度や文書全体での重要性に基づき検索クエリとの関連度を順位付けするアルゴリズムです。
- ハイブリッド検索
- ハイブリッド検索とは、複数の検索方法を組み合わせた検索手法です。主に、ベクトル検索とキーワード検索を組み合わせます。
- LangChain
- LangChainは、大規模言語モデルを用いたアプリケーションを構築するためのフレームワークです。
- langchain.com
- LangChain GitHub リポジトリ
- OpenSearch
- OpenSearchは、ベクトル検索などの機能を有する検索エンジンです。
- opensearch.org
- OpenSearch GitHub リポジトリ
- OpenSearch-Dashboards GitHub リポジトリ